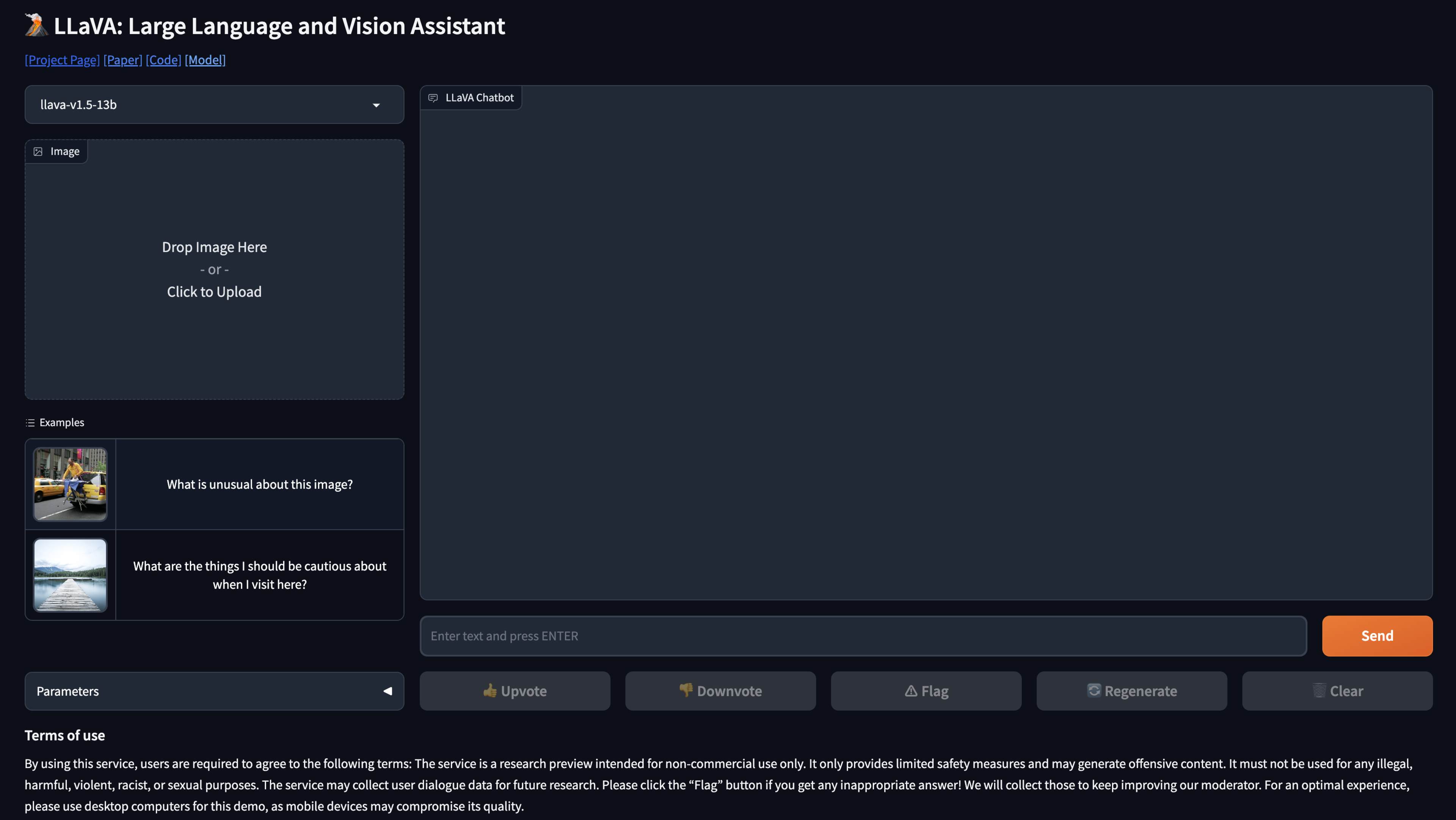
I actually think this LlaVA model might be better than GPT4V 😯 llava.hliu.cc

LLaVA is an advanced AI model that combines a vision encoder and large language models for general-purpose visual and language understanding. It is a novel end-to-end trained multimodal model that aims to achieve impressive chat abilities while mimicking the behavior of multimodal models like GPT-4.
The key focus of LLaVA is visual instruction tuning, which involves using machine-generated instruction-following data to enhance the capabilities of large language models in understanding and generating content in the multimodal domain. By leveraging language-only models like GPT-4, LLaVA generates multimodal language-image instruction-following data, bridging the gap between language and vision.
With LLaVA, users can benefit from an AI-powered assistant that excels in chat capabilities and offers accurate responses to a wide range of visual instructions. It sets a new state-of-the-art accuracy on science question answering tasks and provides impressive results on unseen images and instructions.
Key Features of LLaVA:
LLaVA is a significant advancement in the field of multimodal AI, providing researchers, developers, and AI enthusiasts with a powerful tool for exploring, studying, and developing state-of-the-art models that can understand and generate content in both language and vision domains.
To learn more about LLaVA and access the resources related to the project, including the code, model, and dataset, visit the LLaVA website.
I actually think this LlaVA model might be better than GPT4V 😯 llava.hliu.cc
🛒 LLaVA-1.5 skillfully converts an image of groceries into JSON, following the given instructions, like ChatGPT-Vision #GPT4V! A demonstration of streamlined visual analysis and smart data conversion in action! 🧵2/5 x.com/mckaywrigley/s…

ChatGPT Vision takes an image of groceries and converts it to JSON based on the instructions. GPT-4V is an image processing supertool.


Can’t get your hands on GPT-4 Vision? Here is your solution! LLaVa is here, and it’s FREE, it’s open-source, and it’s instant. No waits, no costs, just pure AI empowerment!
GPT-4 Vision has a FREE competitor LLaVA: Large Language and Vision Assistant. I asked it to explain Elon’s meme - and it got it!
LLaVa could be the answer to label anime images using natural language.


Asking LLaVA 1.5 to roast me.

LLaVA is trained on 8 A100 GPUs with 80GB memory. They use a similar set of hyperparameters as Vicuna in finetuning. Both hyperparameters used in pretraining and finetuning are provided below.

LLaVa was tested against a messy parking space image against GPT-4 Vision. And it was flawless (see video).
🔍 Tested Llava 1.5 vs Bard in vision capabilities - results were eye-opening! Fed both a vegetable image & asked to get the name of vegetable, count, shape, colour & details: Bard detected only 2 out of 8 veggies correctly and miscounted them. Meanwhile, Llava 1.5 impressively…




Don’t have access to GPT-4V yet? Try LLaVA chatbot, a free open source model hosted on HuggingFace: llava.hliu.cc

Really impressive results from the newest LLaVA release.
🚀 LLaVA-1.5 is out! Achieving SoTA on 11 benchmarks, with simple mods to original LLaVA! Utilizes merely 1.2M public data, trains in ~1 day on a single 8-A100 node, and surpasses methods that use billion-scale data. 🔗arxiv.org/abs/2310.03744 🧵1/5

Syte is a visual AI-powered product discovery platform for eCommerce. It enhances search results, navigation, and SEO, while also providing visually similar and complementary product recommendations to boost conversions.
Dataminr is a real-time AI platform that detects high-impact events and emerging risks from publicly available data, empowering organizations to respond effectively and manage crises with confidence.
A free, AI-powered tool for educational and experimental wound analysis, offering accurate assessments and treatment insights.
Join 80,000+ Founders, Executives, Investors, and Developers